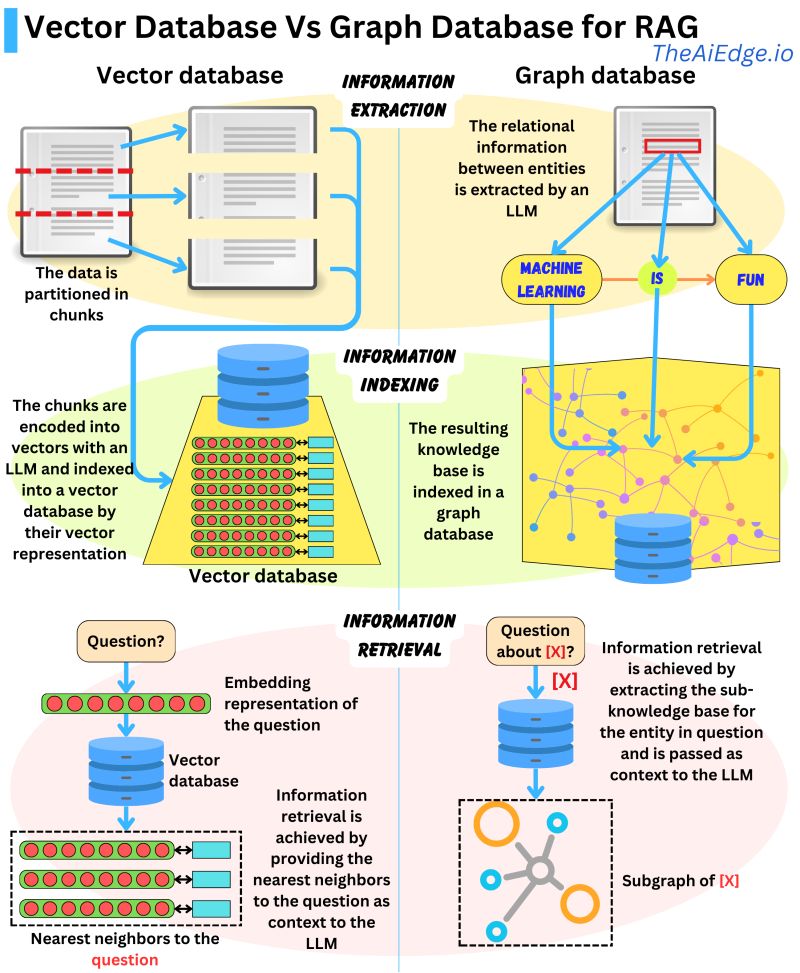
In the evolving landscape of database technologies, understanding the distinctions between various database types is crucial for developers and data scientists alike. Vector databases (Vector DB) and graph databases (Graph DB) serve unique purposes, yet both play significant roles in data management and analysis. As organizations increasingly rely on data-driven decisions, choosing the right database can drastically affect performance, scalability, and the ability to derive insights from vast datasets.
Vector databases are designed to handle high-dimensional data, making them ideal for applications like machine learning, natural language processing, and image recognition. On the other hand, graph databases excel in managing complex relationships among data points, which is particularly beneficial in social networks, recommendation systems, and fraud detection. This article aims to delve deeper into the characteristics, advantages, and use cases of vector DB and graph DB, providing a clearer picture for those looking to make informed choices in database technologies.
Ultimately, the decision between vector DB vs graph DB hinges on specific project requirements and the nature of the data involved. By exploring the fundamental differences and similarities between these two types of databases, we can better understand their respective strengths and weaknesses, and how they can be leveraged in various scenarios.
What is a Vector Database?
A vector database is a specialized type of database designed to store and manage high-dimensional vectors. Vectors represent data points in a multi-dimensional space, making them particularly useful for applications that require similarity searches or pattern recognition. For instance, in machine learning, each data point can be represented as a vector, capturing its features and attributes. This allows for efficient querying and retrieval of similar data points based on distance metrics.
Key Features of Vector Databases
- High-Dimensional Data Handling: Vector databases excel in managing and querying high-dimensional data.
- Similarity Search: They provide efficient algorithms for searching similar vectors, which is crucial in applications like recommendation systems.
- Scalability: Vector databases are designed to handle large volumes of data, making them ideal for big data applications.
- Fast Retrieval: With optimized indexing techniques, they enable rapid data retrieval, enhancing performance for real-time applications.
What is a Graph Database?
Graph databases are designed to manage and analyze relationships between data points efficiently. They use graph structures consisting of nodes, edges, and properties to represent and store data. This enables them to model complex relationships and connections, making them particularly useful for applications that require deep relationships and traversals, such as social networks, fraud detection, and knowledge graphs.
Key Features of Graph Databases
- Relationship-Centric: Graph databases prioritize relationships, allowing for easy representation and querying of connected data.
- Flexible Schema: They support a flexible schema, enabling developers to adapt the database structure as requirements evolve.
- Complex Queries: Graph databases can efficiently execute complex queries involving multiple relationships, which is challenging for traditional databases.
- Traversal Efficiency: They are optimized for traversing relationships, making them ideal for applications requiring deep data exploration.
What are the Use Cases for Vector DB?
Vector databases are particularly well-suited for applications involving high-dimensional data. Some common use cases include:
- Machine Learning: Storing feature vectors for training and inference, allowing for quick similarity searches.
- Natural Language Processing: Managing word embeddings and contextual representations for tasks like sentiment analysis and language translation.
- Image Recognition: Storing image feature vectors to enable fast retrieval of similar images based on visual content.
- Recommendation Systems: Leveraging user and item vectors to provide personalized recommendations based on user preferences.
What are the Use Cases for Graph DB?
Graph databases are ideal for scenarios that require in-depth analysis of relationships. Some key use cases include:
- Social Networks: Managing user profiles, connections, and interactions to analyze user behavior and influence.
- Fraud Detection: Analyzing transaction patterns and relationships to identify suspicious activities.
- Recommendation Systems: Utilizing relationships between users and items to provide contextual recommendations.
- Knowledge Graphs: Representing entities and their relationships for enhanced information retrieval and insights.
How Do Vector DB and Graph DB Compare in Performance?
When considering vector DB vs graph DB, performance can vary significantly depending on the nature of the queries and the underlying data structure. Here are some key performance considerations:
- Query Type: Vector databases excel in similarity searches and quick retrieval of high-dimensional data, while graph databases shine in traversing complex relationships and executing intricate queries.
- Data Structure: The efficiency of data retrieval can depend on the underlying data structure; vector databases use indexing techniques tailored for high-dimensional data, whereas graph databases leverage graph traversal algorithms.
- Scalability: Both types of databases are designed for scalability, but their performance may vary based on the volume of data and the complexity of relationships.
Which Database Should You Choose: Vector DB or Graph DB?
The decision between vector DB vs graph DB ultimately depends on the specific requirements of your project. Here are some factors to consider:
- Data Type: If your data is inherently high-dimensional and requires similarity searches, a vector database is likely the better choice. Conversely, if your data is relational and involves complex connections, a graph database may be more appropriate.
- Use Case: Consider the primary use case of your application. For example, machine learning tasks often benefit from vector databases, while social network analysis is better suited for graph databases.
- Performance Needs: Evaluate the performance needs of your application. If rapid retrieval of similar data points is crucial, vector databases may provide an advantage, while graph databases can optimize complex queries involving relationships.
Conclusion: The Final Thoughts on Vector DB vs Graph DB
In summary, both vector databases and graph databases serve distinct purposes in the realm of data management and analysis. Understanding the differences between vector DB vs graph DB is essential for making informed decisions about which technology to adopt for your specific application needs. By carefully evaluating the features, use cases, and performance considerations, organizations can leverage the strengths of each database type to enhance their data-driven strategies and achieve better outcomes.
You Might Also Like
Unveiling The Journey Of Chris Pickett: A Multifaceted TalentNHTDB: Understanding The New Heights Of Transportation Data
Unlocking The Mystique Of The Golden Cape RS3
Exploring The Innovative Realm Of Wolf Carbon Solutions
Unlocking Convenience: The Benefits Of Eastern Bank ATM
Article Recommendations
- How Long Does Hepatitis Live Outside The Body
- Hughes Net Bill
- Oldest Dad In The World
- Cons For Electric Cars
- Are Egg Cartons Recyclable
- Shield Recipe For Minecraft
- How To Tag On Ig Story
- What Does Tkl Mean Keyboard
- Forest Sunlight
- Brad Pitt Height